
videobrev: YouTube Transcripts & AI Summaries
A YouTube filter for people with limited patience: grab the transcript, get the AI summary, and decide if the video deserves your evening.
This project started for a very practical reason: a friend kept sending me long YouTube videos, and I wanted to know whether they were worth watching before donating half my evening to them.
So VideoBrev became a kind of YouTube filter. Grab the transcript, run it through an LLM, and give me the quick version first. The goal is not "replace the video". It’s "help me decide whether this deserves my eyeballs".
Tech Stack Talk
The interesting bits:
- Learning how to extract YouTube transcripts
- Stream AI summaries in real-time using Server-Sent Events
- AI model selection and handling videos from seconds to 8+ hours (~76k tokens)
- First time using this tech stack and shipped a working project: Golang, SolidJS, UnoCSS
- Multi-provider LLM support (Gemini, Claude, OpenAI, Groq, OpenRouter)
- Circuit breaker pattern for LLMs, because AI APIs are still a bit like genius interns with unreliable calendars
Real stats (30 days, no SEO, 2 Reddit posts):
This was enough to prove that real people were using it, which is always a nice surprise:
- 122 unique devices
- 46 requests completed
- Avg transcript extraction: 1.3 seconds
- Avg AI summary: 6.27 seconds end-to-end
Getting YouTube Transcripts
Getting YouTube transcripts is one of those tasks that feels oddly secretive, like everyone knows there’s a method but nobody wants to say it too loudly in case the wall starts listening.
I won’t spell out every detail here, mostly because these integrations tend to be fragile and YouTube changes things often. The short version is that there’s a rough two-step API flow, it’s not documented particularly well, and the open source community is doing a lot of the heavy lifting whenever it shifts.
Since shipping VideoBrev, YouTube changed things at least three times in ways that broke transcript extraction. The fixes were small, but the lesson was clear: if your product depends on someone else’s data pipe, maintenance is not optional. It’s rent.
AI Model Choice
The part people miss is that model choice is not just about price and speed. Models have personalities. Not in a mystical sense. More in the sense that, after a while, you learn what each one tends to do well, what it fumbles, and how often it falls over at inconvenient moments.
At first I assumed any cheap, fast model would be fine because the task sounded simple: summarise a transcript. Then two problems showed up:
- If the model was not "smart" enough, the summaries were actually missing lots of key info
- LLM inference endpoints have notoriously bad uptimes (compared to non-LLM software)
The first issue mattered a lot. If the summary skips the useful bits, the whole product becomes a very confident waste of time. Longer transcripts made this worse. An eight-hour Python tutorial at roughly 76k transcript tokens was enough to expose which models were just not up to the job.
Here are the models I tested and disabled:
DISABLED_MODELS:
- qwen-qwq-32b
- llama-3.1-8b-instant
- gpt-4o-mini
- meta-llama/llama-4-scout-17b-16e-instruct
- meta-llama/llama-4-maverick-17b-128e-instruct
- mistralai/mistral-nemo
- qwen/qwen-turbo
The optimisation target here was simple: fast, cheap, and smart enough. A lot of models managed two out of three. That sounds fine until you realise the missing third one is the entire product.
So I was looking for the cheap end of the Pareto frontier, not just the absolute cheapest thing with a pulse.
Big 3 and Downtime
In ordinary software, we’ve become used to very high uptime. Four nines means about 53 minutes of downtime a year. That is both impressive and, for modern infrastructure, weirdly normal.

| Provider | SLA Uptime | Downtime/yr | Notes |
|---|---|---|---|
| Gemini | 99.5% | 43.8 hrs | Provides financial credits for missed SLA |
| OpenAI | 99.9% | 8.76 hrs | Enterprise customers only |
| Claude | 99.5% | 43.8 hrs | Best effort, Priority Tier |
For a small app builder, Gemini via Vertex looked like the best deal on paper because you could get an SLA without needing an enterprise sales ritual.
Then I looked at the last 90 days of public status data and compared that with the promises.
Downtime in the past 90 days (10 Dec 2025)
| Provider | Downtime | Yearly Projected | SLA Target | Met SLA? |
|---|---|---|---|---|
| Gemini | 97.4 hrs | 95.5% (~1.3 nines) |
99.5% | No |
| OpenAI | 72.7 hrs | 96.6% (~1.5 nines) |
99.9% | No |
| Claude | 11.8 hrs | 99.5% (~2.3 nines) |
99.5% | Yes |
Note: SLA targets are product-tier specific (Vertex AI, OpenAI Enterprise, Claude Priority Tier) and may not apply to the same endpoints tracked in the status pages above.
The punchline is not subtle: AI endpoints are still much less reliable than the rest of the software stack we’re used to. Even for a small app, "hope the provider behaves today" is not a strategy. It’s a coin toss wearing a lanyard.
That is what pushed me to build circuit breakers.
AI Models Chosen and Circuit Breakers
Here are the models I ended up using:
DEFAULT_LLM_PROVIDER_SHORT_CONTENT=openrouter
DEFAULT_LLM_PROVIDER_LONG_CONTENT=google
DEFAULT_GOOGLE_MODEL=gemini-2.0-flash
DEFAULT_OPENROUTER_MODEL="meta-llama/llama-3.1-8b-instruct" # Cerebras only
DEFAULT_ANTHROPIC_MODEL=claude-3-5-haiku-latest
DEFAULT_OPENAI_MODEL=gpt-4.1-mini
Why so many? Because short and long videos behave differently. For short videos, the "smart enough" problem usually doesn’t show up, so I could prioritise cost and speed much more aggressively.
Why not Groq for everything? In my testing, I sometimes saw long startup waits before inference even began. If the queue burns ten seconds up front, the cheap fast model is no longer looking especially fast.
Here’s the cost table I was using to compare, from cheapest to most expensive:
| Provider | Model | Input Cost | Output Cost |
|---|---|---|---|
| OpenRouter | Meta Llama 3.1 8B (Groq) | $0.05 | $0.08 |
| OpenRouter | Meta Llama 3.1 8B (Cerebras) | $0.10 | $0.10 |
| Gemini 2.0 Flash | $0.10 | $0.40 | |
| Gemini 2.5 Flash Preview | $0.15 | $0.60 | |
| OpenAI | GPT-4.1-mini | $0.40 | $1.60 |
| Anthropic | Claude 3.5 Haiku | $0.80 | $4.00 |
Gemini Flash models were close to ideal for this workload: good summaries, decent speed, and low enough cost. They handled very long transcripts well. But I still wanted something even cheaper for short videos, and Gemini also threw enough overload errors in testing to make fallback logic necessary anyway.
That’s where the circuit breaker pattern came in.
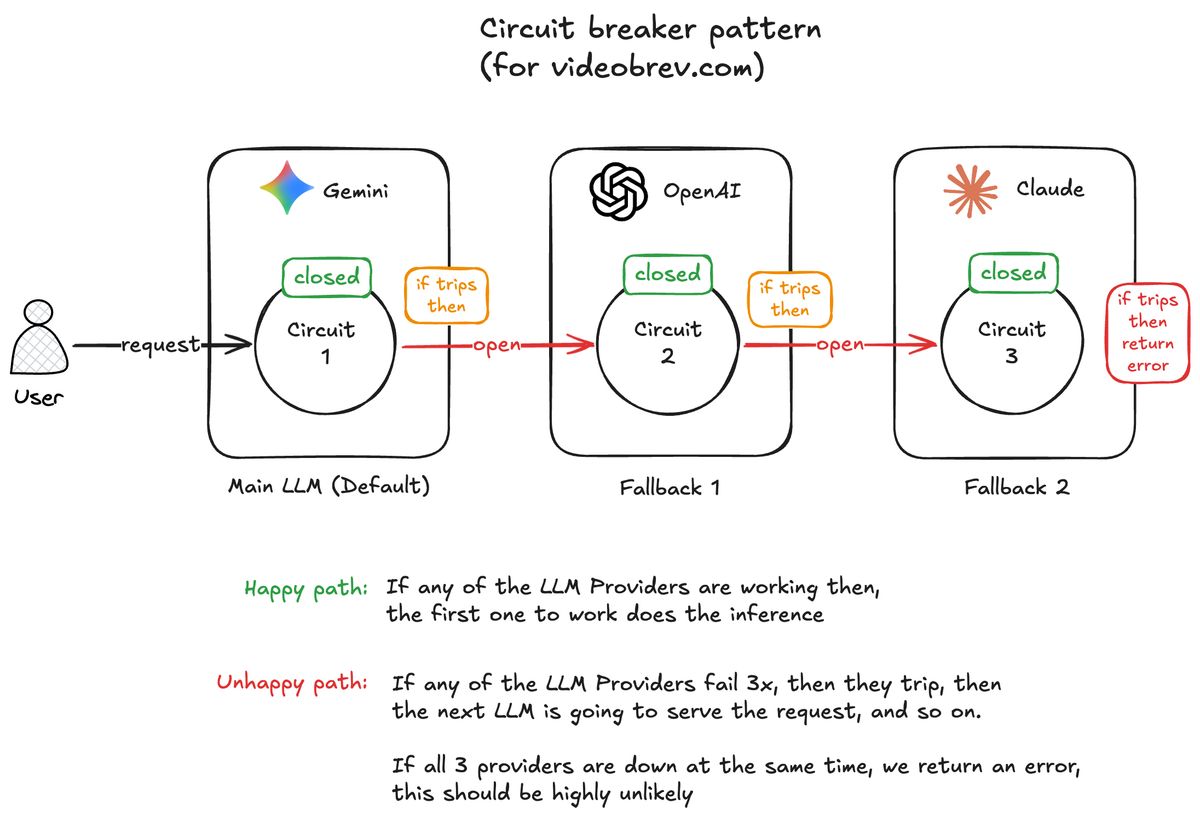
Circuit breakers are a clean fit for flaky third-party services. When one provider starts failing, you stop sending it traffic for a while and fall back to the next option. Then you test it again later to see if it has recovered. Simple idea. Very useful.
Each provider in the fallback chain has its own circuit breaker with three states:
- Closed - Provider is healthy, requests go through normally
- Open - Provider is failing, skip it entirely and move to the next fallback
- Half-Open - Cautiously testing if the provider has recovered
So I layered backup providers into two separate fallback chains. Short videos have this priority: Llama 3.1, Gemini Flash 2, GPT-4.1-mini Long videos have this priority: Gemini Flash 2, GPT-4.1-mini, Claude 3.5 Haiku
If an API fails three times, that circuit opens for 60 seconds and traffic moves to the next provider. GPT-4.1-mini and Claude 3.5 Haiku are not my favourite options on cost, but reliability likes diversity.
Example: You submit a 10-minute video, so we start with Gemini 2.0 Flash. If that provider starts returning errors, the circuit breaker tracks the failure rate. Once we've seen at least 3 requests and 60% or more have failed, the breaker trips to Open. For the next 60 seconds, we don't even attempt Gemini 2.0 Flash. Requests immediately fall through to the next provider (OpenAI GPT-4.1-mini in this case).
After that 60-second timeout, the breaker enters Half-Open and lets exactly one test request through. If it succeeds, we're back in business with that provider. If it fails, back to Open for another minute.
This keeps the app responsive when providers are having a bad day. Instead of politely queueing for more failure, the system routes around the problem.
Prompting
Prompting is both simpler and harder than people say.
One practical approach is to dump your goals, constraints, and examples into a rough brief, then ask the model to help shape the prompt. That’s more or less how I started. Trial and error first, then refinement.
Different models also respond differently to the same prompt. Some need more steering. Some need less. If you’re trying to support multiple models with one prompt, more detail usually helps.
Prompt evolution:
- V1: "Summarize this transcript" → hallucinated names, wrong terms
- V2: Added ASR (Automatic Speech Recognition) error handling instructions, still not a completely solved problem
- V3: Structured output (TLDR + detailed sections)
Backend and Frontend Architecture
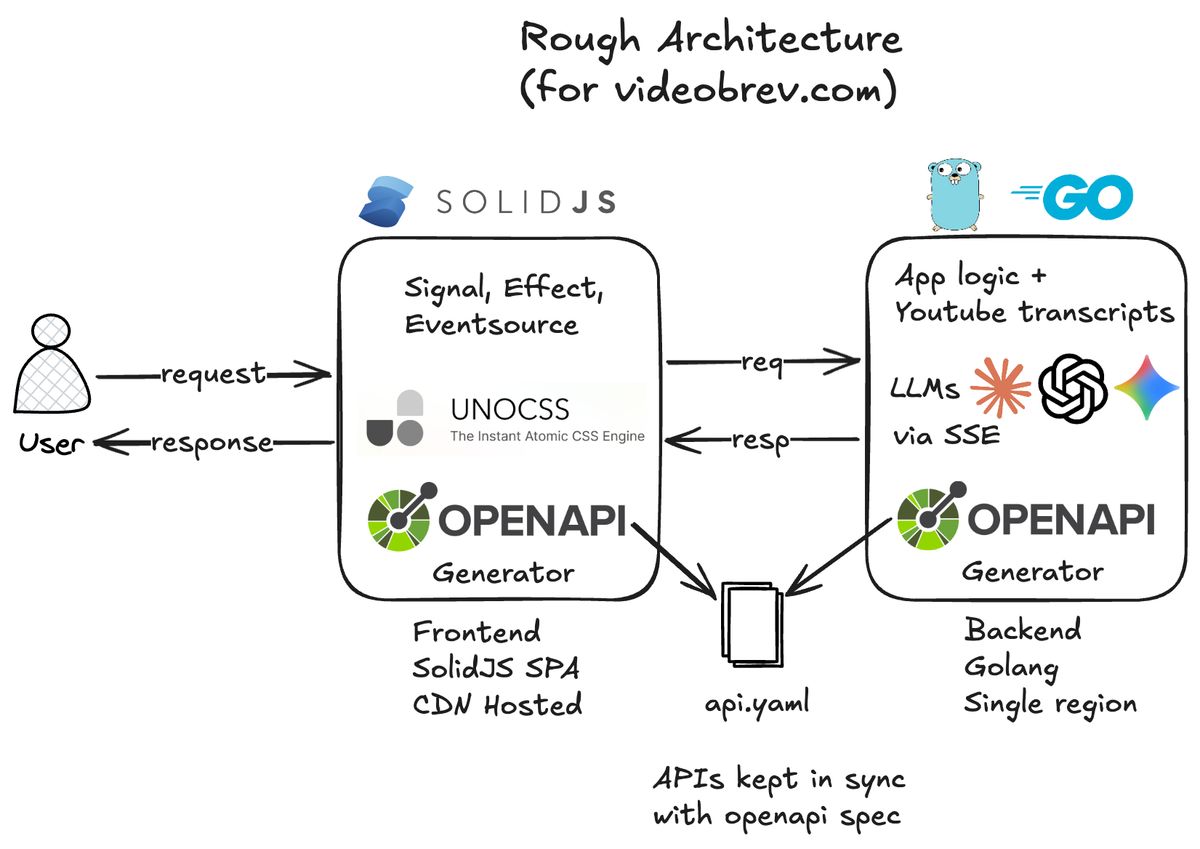
The app uses a Go backend with a SolidJS SPA frontend. At the time I wanted to try SolidJS and UnoCSS, and both were enjoyable to work with. Fast, lightweight, good developer experience.
That said, with hindsight I probably wouldn’t choose the same stack again for this project. I’d likely move it toward a Go MPA with Datastar and simplify the whole shape of the app.
Frontend
SolidJS did make me appreciate JSX more than I expected. But frontend speed is not just about the framework. It’s also about the ecosystem around it, and that’s where larger ecosystems still have a real edge.
I came into web development during the Svelte hype years, so React never became my default instinct. Part of that is taste. I like lighter tools when they’re good enough. I’m always trading off raw ecosystem size against performance and simplicity.
UnoCSS had a similar tradeoff. Fast and flexible, yes. But fewer ready-made UI patterns meant more tinkering than I really wanted. That tradeoff matters when the goal is to ship, not just admire your tooling choices in the mirror.
Why SSE over WebSockets: Simpler protocol, unidirectional is sufficient, automatic reconnection, HTTP/2 compatible.
Key Takeaways
Technical:
- AI model providers are still far off from the reliability we expect from regular non-LLM apps
- Circuit breakers should be mandatory for AI services, but careful prompting is needed for harder tasks than just summarisation
- Per-model prompts are likely better than one prompt for all models
- If you are going to use one prompt for all models, give it more detail and instruction
- Prompting is important because it is one of the few levers you directly control
Product:
- Building a business on someone else's data has to be done with care and maintenance in mind
- Edge cases break everything, so test the 8-hour videos early
Future Work
I’ll probably leave this app as an artifact rather than fully rebuild it, but the ideas are still useful.
Architecture:
- Golang MPA with templ and Datastar, which removes the frontend framework and the OpenAPI-spec coupling
Features:
- Caching layer for popular videos
- Timestamp references, because model citations are still weak without vector search or something similar
- Jargon web lookup. For example, the fast cheap models still don’t always know what MCP (Model Context Protocol) stands for
Product:
- Chrome extension for in-page summaries
- Saved transcripts and summaries (user accounts)
- Export to Notion, Obsidian, markdown